


 降低存储压力
降低存储压力
本文介绍如何对 DeepFlow 进行配置以降低 ClickHouse 的存储开销。
# 1. 配置项总览
在介绍具体的配置项之前,我们首先看看 DeepFlow Agent 采集的主要数据类型都有哪些。从 ClickHouse 中数据库、数据表的角度来看,数据主要有如下几类:
flow_log.l4_flow_log:流日志。基于 cBPF 流量数据计算出的 TCP/UDP 五元组流日志,每条流日志包含包头五元组字段、标签字段、性能指标,每条流日志平均大约消耗 150 字节存储空间。flow_log.l7_flow_log:调用日志。基于 cBPF 流量数据、eBPF 函数调用数据计算出的 HTTP/gRPC/MySQL 等应用协议的调用日志,每条调用日志包含调用的关键请求/响应字段、标签字段、性能指标,每条调用日志平均大约占用 70 字节存储空间,主要取决于头部字段的长度,各种应用协议存储的头部字段详见文档。flow_metrics:指标数据。基于流日志和调用日志聚合计算得到的指标数据,默认聚合生成 1m、1s 两种时间精度的指标。由于这些指标数据是聚合得到的,体量不大,一般消耗的存储空间仅仅是流日志或调用日志的 1/10 左右。event.perf_event:性能事件。目前主要存储进程的文件读写事件,每个事件包含进程名、文件名、读写性能指标等字段,每个事件大约占用 80 字节。profile:持续剖析。存储开启了持续剖析功能的进程的函数调用栈,默认仅 deepflow-agent 和 deepflow-server 进程开启 eBPF OnCPU Profile。
DeepFlow 有丰富的配置可以用于降低 ClickHouse 的存储开销,下图中进行了汇总。
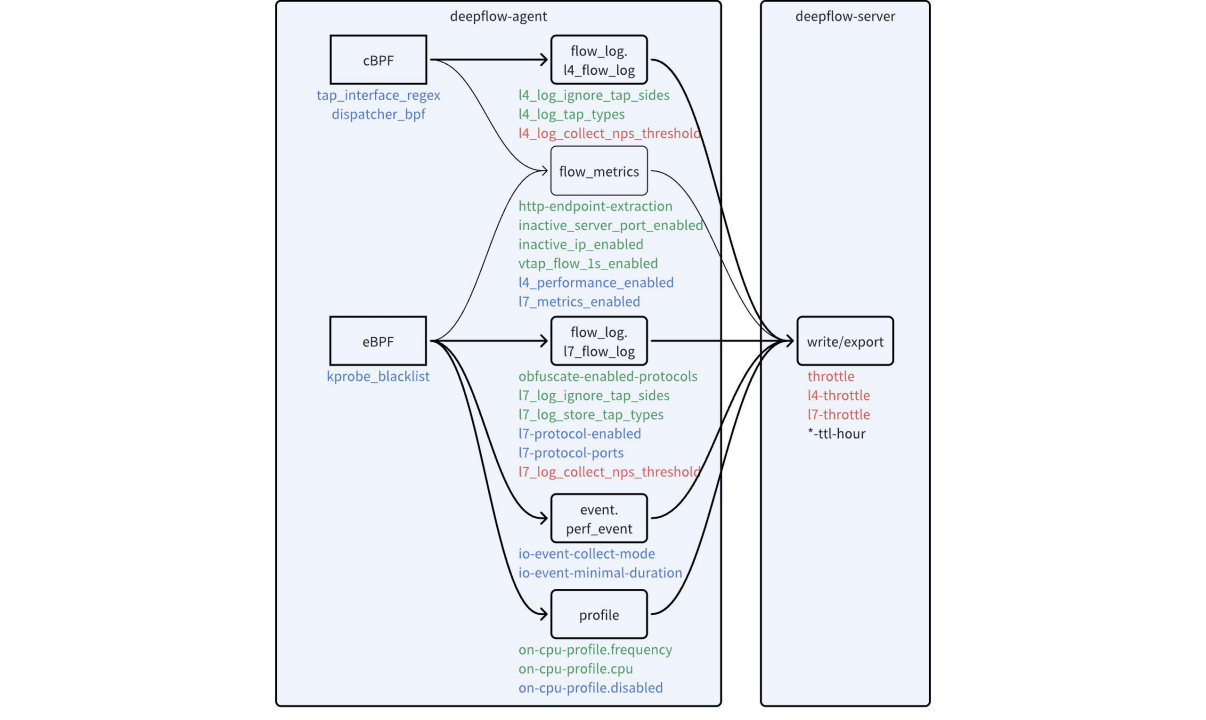
可用于降低数据量的配置项
上图中的配置参数根据其用途可以分为四类:
- 黑色:用于设置数据保存时长。不同类型的数据通常需要设置不同的保存时长。
- 绿色:用于降低数据精细程度。通过修改配置,可以调整各类数据的精细程度,直接达到降低存储压力的目的。
- 蓝色:用于关闭不关心的数据。通过修改配置,可以关闭一些自身不关心的功能,或者屏蔽一部分不关心的流量,从而达到降低存储压力的目的。
- 红色:用于设置过载保护阈值。Agent 和 Server 为了保护自身避免过载,暴露了采集和存储数据速率的阈值配置项,避免采集和写入过量数据。
# 2. 动手之前预估效果
调整配置之前应该在 ClickHouse 中确认对应数据的储存消耗,预先评估配置调整会带来的收益。下面这些 ClickHouse 命令能够帮助你评估特定数据表的存储开销。
查看所有数据表的行数和空间消耗,确认哪些数据表占用了最多的存储空间:
WITH sum(bytes_on_disk) AS size SELECT database, table, formatReadableSize(sum(data_uncompressed_bytes)) AS "压缩前总大小", formatReadableSize(sum(bytes_on_disk)) AS "压缩后总大小", sum(rows) AS "总行数", sum(data_uncompressed_bytes)/sum(rows) AS "压缩前平均每行长度", sum(bytes_on_disk)/sum(rows) AS "压缩后平均每行长度" FROM system.parts GROUP BY database, table ORDER BY size DESC;
WITH sum(bytes_on_disk) AS size
SELECT
database,
table,
formatReadableSize(sum(data_uncompressed_bytes)) AS `压缩前总大小`,
formatReadableSize(sum(bytes_on_disk)) AS `压缩后总大小`,
sum(rows) AS `总行数`,
sum(data_uncompressed_bytes) / sum(rows) AS `压缩前平均每行长度`,
sum(bytes_on_disk) / sum(rows) AS `压缩后平均每行长度`
FROM system.parts
GROUP BY
database,
table
ORDER BY size DESC
┌─database────────┬─table────────────────────────────────────┬─压缩前总大小─┬─压缩后总大小─┬────总行数─┬─压缩前平均每行长度─┬──压缩后平均每行长度─┐
│ flow_log │ l7_flow_log_local │ 16.58 GiB │ 3.15 GiB │ 47231817 │ 377.02479955408023 │ 71.69953315579623 │
│ flow_log │ l4_flow_log_local │ 4.84 GiB │ 1.51 GiB │ 10487780 │ 495.46614078479905 │ 154.46138525026268 │
│ profile │ in_process_local │ 2.24 GiB │ 349.19 MiB │ 10325238 │ 233.1437255974148 │ 35.46215912892274 │
│ flow_metrics │ network_map.1s_local │ 1.95 GiB │ 261.58 MiB │ 5267001 │ 398.20784256543715 │ 52.07621016210174 │
│ flow_metrics │ network.1s_local │ 1.01 GiB │ 159.70 MiB │ 3027870 │ 357.85661273436443 │ 55.30619544432225 │
│ flow_metrics │ application.1s_local │ 932.36 MiB │ 129.11 MiB │ 8225431 │ 118.85691983799998 │ 16.459093876053426 │
│ deepflow_system │ deepflow_system_local │ 1.55 GiB │ 117.64 MiB │ 18478240 │ 89.79716217561845 │ 6.675736920832287 │
│ flow_metrics │ application_map.1s_local │ 691.41 MiB │ 65.07 MiB │ 4128212 │ 175.6193790435181 │ 16.52821560520632 │
│ flow_metrics │ network_map.1m_local │ 331.22 MiB │ 57.66 MiB │ 818085 │ 424.5371263377277 │ 73.90728347298875 │
│ flow_metrics │ application_map.1m_local │ 228.35 MiB │ 28.72 MiB │ 1435956 │ 166.75001462440352 │ 20.973729000052927 │
│ flow_metrics │ network.1m_local │ 121.96 MiB │ 27.08 MiB │ 328060 │ 389.8104432116076 │ 86.55356946899957 │
│ flow_metrics │ application.1m_local │ 97.90 MiB │ 16.84 MiB │ 870320 │ 117.95215897600882 │ 20.283444020590128 │
│ event │ perf_event_local │ 2.84 MiB │ 1.24 MiB │ 16543 │ 180.1239194825606 │ 78.70126337423683 │
└─────────────────┴──────────────────────────────────────────┴──────────────┴──────────────┴───────────┴────────────────────┴─────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
查询某个数据表每天的空间消耗,例如查询 l7_flow_log 每天的空间消耗,确认某个数据表每天的空间消耗,评估该类数据如何设置保存时长:
WITH sum(bytes_on_disk) AS size SELECT SUBSTRING(partition, 1, 10) AS date, formatReadableSize(sum(data_uncompressed_bytes)) AS "压缩前总大小", formatReadableSize(sum(bytes_on_disk)) AS "压缩后总大小", sum(rows) AS "总行数", sum(data_uncompressed_bytes)/sum(rows) AS "压缩前平均每行长度", sum(bytes_on_disk)/sum(rows) AS "压缩后平均每行长度" FROM system.parts WHERE `table` = 'l7_flow_log_local' GROUP BY date ORDER BY date DESC;
WITH sum(bytes_on_disk) AS size
SELECT
substring(partition, 1, 10) AS date,
formatReadableSize(sum(data_uncompressed_bytes)) AS `压缩前总大小`,
formatReadableSize(sum(bytes_on_disk)) AS `压缩后总大小`,
sum(rows) AS `总行数`,
sum(data_uncompressed_bytes) / sum(rows) AS `压缩前平均每行长度`,
sum(bytes_on_disk) / sum(rows) AS `压缩后平均每行长度`
FROM system.parts
WHERE table = 'l7_flow_log_local'
GROUP BY date
ORDER BY date DESC
┌─date───────┬─压缩前总大小─┬─压缩后总大小─┬───总行数─┬─压缩前平均每行长度─┬─压缩后平均每行长度─┐
│ 2023-12-27 │ 3.50 GiB │ 681.83 MiB │ 10049374 │ 374.3181802169966 │ 71.14405494312382 │
│ 2023-12-26 │ 5.13 GiB │ 1012.92 MiB │ 14397814 │ 382.63502848418517 │ 73.76948966002756 │
│ 2023-12-25 │ 5.73 GiB │ 1.07 GiB │ 16340447 │ 376.4205308459432 │ 70.36901530294735 │
│ 2023-12-24 │ 2.22 GiB │ 436.62 MiB │ 6432796 │ 370.22603095139345 │ 71.17070586413746 │
└────────────┴──────────────┴──────────────┴──────────┴────────────────────┴────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
根据某个字段的值,区分统计空间消耗。例如:查看 l7_flow_log 表中不同应用协议(l7_protocol)的行数,以及对应的 request_resource 字段的平均长度,评估是否关闭某种应用协议的解析:
SELECT dictGet(flow_tag.int_enum_map, 'name', ('l7_protocol', toUInt64(l7_protocol))) AS "应用协议", count(0) AS "行数", sum(length(request_resource))/count(l7_protocol) AS "平均 request_resource 长度", sum(length(request_resource))/sum(if(request_resource !='', 1, 0)) AS "平均非空 request_resource 长度" FROM flow_log.l7_flow_log WHERE time>now()-86400 GROUP BY l7_protocol ORDER BY "行数" DESC;
SELECT
dictGet(flow_tag.int_enum_map, 'name', ('l7_protocol', toUInt64(l7_protocol))) AS `应用协议`,
count(0) AS `行数`,
sum(length(request_resource)) / count(l7_protocol) AS `平均 request_resource 长度`,
sum(length(request_resource)) / sum(if(request_resource != '', 1, 0)) AS `平均非空 request_resource 长度`
FROM flow_log.l7_flow_log
WHERE time > (now() - 86400)
GROUP BY l7_protocol
ORDER BY `行数` DESC
┌─应用协议───┬─────行数─┬─平均 request_resource 长度─┬─平均非空 request_resource 长度─┐
│ HTTP │ 15307526 │ 50.94938901296003 │ 51.16722749422727 │
│ MySQL │ 12762197 │ 67.32974729977919 │ 103.38747090527679 │
│ DNS │ 9271394 │ 41.6790123470106 │ 41.6790123470106 │
│ HTTP2 │ 4561075 │ 0.9742264707333249 │ 1.0020964209295697 │
│ TLS │ 3422769 │ 14.613528403465148 │ 23.354457466682167 │
│ Redis │ 2140668 │ 89.61926931219601 │ 92.19873624192489 │
│ gRPC │ 957471 │ 13.709391720480307 │ 23.696586596959204 │
│ N/A │ 79113 │ 0 │ nan │
│ Custom │ 4802 │ 1 │ 1 │
│ PostgreSQL │ 1125 │ 81.112 │ 81.112 │
│ MongoDB │ 108 │ 1.3703703703703705 │ 2.3125 │
└────────────┴──────────┴────────────────────────────┴────────────────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
查看 l7_flow_log 表中不同观测点(observation_point)的行数,评估是否关闭某些观测点处采集的调用日志:
SELECT observation_point, dictGet(flow_tag.string_enum_map, 'name', ('observation_point', observation_point)) AS "观测点", count(0) AS "行数" FROM flow_log.l7_flow_log WHERE time>now()-86400 GROUP BY observation_point ORDER BY "行数" DESC;
SELECT
observation_point,
dictGet(flow_tag.string_enum_map, 'name', ('observation_point', observation_point)) AS `观测点`,
count(0) AS `行数`
FROM flow_log.l7_flow_log
WHERE time > (now() - 86400)
GROUP BY observation_point
ORDER BY `行数` DESC
┌─observation_point─┬─观测点─────────┬─────行数─┐
│ c │ 客户端网卡 │ 15034372 │
│ s │ 服务端网卡 │ 9343403 │
│ c-p │ 客户端进程 │ 9179406 │
│ s-p │ 服务端进程 │ 5723075 │
│ rest │ 其他网卡 │ 3170534 │
│ s-nd │ 服务端容器节点 │ 2796958 │
│ c-nd │ 客户端容器节点 │ 2334083 │
│ local │ 本机网卡 │ 1365403 │
│ s-app │ 服务端应用 │ 89280 │
│ app │ 应用 │ 80079 │
│ s-gw │ 网关到服务端 │ 11 │
└───────────────────┴────────────────┴──────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
根据某个字段的值,区分统计空间消耗。例如:查看 event.perf_event 表中不同 duration 的数据行数:
SELECT count(), min(duration) AS min_duration_us, max(duration) AS max_duration_us, toUInt64(duration/1000) AS ms FROM event.perf_event GROUP BY ms ORDER BY ms ASC
SELECT
count(),
min(duration) AS min_duration_us,
max(duration) AS max_duration_us,
toUInt64(duration / 1000) AS ms
FROM event.perf_event
GROUP BY ms
ORDER BY ms ASC
┌─count()─┬─min_duration_us─┬─max_duration_us─┬───ms─┐
│ 233129 │ 1000 │ 1999 │ 1 │
│ 6912 │ 2000 │ 2999 │ 2 │
│ 1209 │ 3000 │ 3999 │ 3 │
│ 552 │ 4000 │ 4999 │ 4 │
│ 320 │ 5002 │ 5996 │ 5 │
│ 187 │ 6000 │ 6992 │ 6 │
│ 119 │ 7030 │ 7997 │ 7 │
│ 103 │ 8003 │ 8992 │ 8 │
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 3. 黑色:设置数据保存时长
deepflow-server 为所有的数据表都提供了保存时长的设置能力,在 server.yaml 中搜寻 -ttl-hour 配置项可以按需设置特定数据表的保存时长。通常你可以将指标类数据(flow_metrics、prometheus 等)设置更长的保存时长,而将日志类数据(flow_log 等)设置更多的保存时长。如你所见,保存时长的精度可以达到小时。
在企业版中你可以直接在 DeepFlow 页面上设置数据的保存时长。社区版仅支持对未创建的数据表设置保存时长,因此当你希望修改某个表的保存时长时,需要先进入 ClickHouse 删除该表然后重启 deepflow-server。
# 4. 绿色:降低数据精细程度
我们首先关注绿色的配置项,调整这些配置能帮助我们对数据的精细程度进行取舍,从而降低存储压力。
对于流日志 flow_log.l4_flow_log:
- 设置
l4_log_ignore_tap_sides,可丢弃部分观测点(observation_point)处采集的流日志。如下图所示,以 K8s 容器环境为例,DeepFlow 默认会采集虚拟网卡和物理网卡上的流日志。当 Pod1 访问 Pod3 时,我们会在沿途的四个网卡上采集到同一股流量的四条流日志。例如我们可以设置此配置项为 c-nd 和 s-nd,来丢弃物理网卡上采集的流日志。关于观测点的详细描述可参考文档。 - 设置
l4_log_tap_types,可丢弃部分网络位置处采集的流日志。当我们让 Agent 处理物理交换机的镜像流量(企业版功能)时,可以通过设置此配置项来控制丢弃指定镜像位置的流日志。特别地,将此配置项设置为[-1]时,将完全关闭流日志数据。
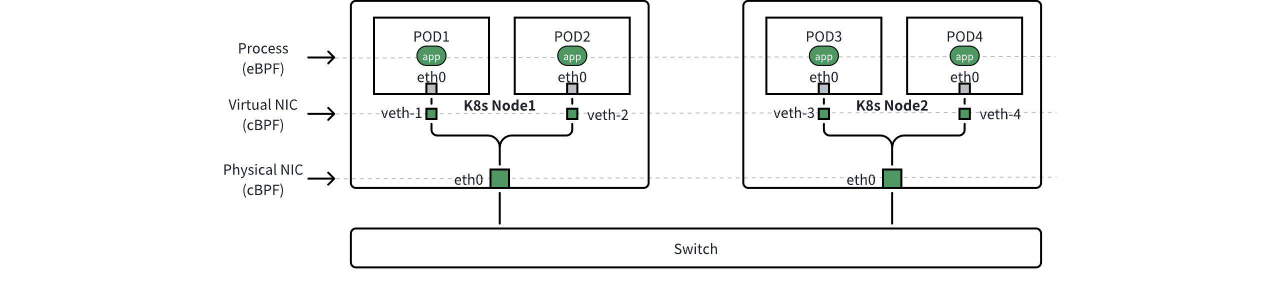
数据的观测点(observation_point)
对于调用日志 flow_log.l7_flow_log:
- 设置
obfuscate-enabled-protocols,可对调用日志的request_resource字段进行脱敏,将其中的变量替换为?。目前支持对 MySQL、PostgreSQL、Redis 协议进行脱敏。由于脱敏后的字段长度会有明显的降低,因此也就能降低存储开销。注意脱敏会增加 deepflow-agent 的 CPU 开销。 - 设置
l7_log_ignore_tap_sides,可丢弃部分观测点(observation_point)处采集的调用日志。以 K8s 容器环境为例,DeepFlow 默认会采集应用进程、虚拟网卡和物理网卡上的调用日志。上图中当 Pod1 访问 Pod3 时,我们会在沿途的两个进程、四个网卡上采集到同一股流量的六条调用日志。例如我们可以设置此配置项为 c-nd 和 s-nd,来丢弃物理网卡上采集的调用日志。 - 设置
l7_log_tap_types,可丢弃部分网络位置处采集的调用日志。当我们让 Agent 处理物理交换机的镜像流量(企业版功能)时,可以通过设置此配置项来控制丢弃指定镜像位置的调用日志。特别地,将此配置项设置为[-1]时,将完全关闭调用日志数据,同时也关闭了分布式追踪功能。
调整流日志和调用日志的上述配置项,并不会影响指标数据 flow_metrics 的准确性。而对于指标数据,虽然消耗的存储空间并不大,但我们也暴露了一些配置项:
- 设置
http-endpoint-extration,可控制如何生成 HTTP 协议的 endpoint 字段。对于 RPC(例如 gRPC/Dubbo 等)协议,endpoint 字段是明确的,通常能从头部直接获取。但 HTTP URI 中究竟哪部分可作为 endpoint 通常是一个难题。默认情况下对于所有的 URI 我们提取前两段作为 endpoint。但2对于某些 API 可能过短,对另一些 API 又过长,此时可以调整此配置项,避免生成爆炸的 endpoint 字段值,也避免生成的 endpoint 无法提供足够的信息量。 - 设置
inactive_server_port_enabled,可将不活跃的 TCP/UDP 端口号存储为server_port = 0,当网络中存在端口扫描流量时,开启此配置能有效降低指标数据的基数。ClickHouse 对指标基数是不敏感的,但降低指标数据的数量可以让查询更快。此配置项默认是开启的。 - 设置
inactive_ip_enabled,可将不活跃的 IP 地址存储为0.0.0.0,当网络中存在 IP 地址扫描流量时,开启此配置能有效降低指标数据的基数。此配置项默认是开启的。 - 设置
vtap_flow_1s_enabled,可关闭 1s 粒度的聚合数据,当不需要高精度指标数据时可选择关闭此配置,此配置项默认是开启的。
对于持续剖析 profile:
- 设置
on-cpu-profile.frequency,可调整函数调用栈的采样频率,默认为 99,表示每秒采样 99 次,即大约每 10ms 采集一次函数调用栈。将此值调低可减少函数调用栈的数据量。 - 设置
on-cpu-profile.cpu,可设置是否区分不同 CPU 核心上的函数调用栈,默认为 0 表示不区分 CPU 核心,存储开销低。当设置为 1 时不同 CPU 核心上的函数调用栈不会聚合。
# 5. 蓝色:关闭不关心的数据
接下来我们看看蓝色的配置项,调整这些配置能够帮助我们关闭不关心的功能,或者屏蔽不关心的流量,从而达到降低存储开销的目的。
对于调用日志 flow_log.l7_flow_log:
- 设置
l7-protocol-enabled,可选择开启解析的应用协议。默认情况下所有应用协议都是开启解析的,如果你对 Kafka、Redis 等某些协议不关心,可将其从列表中删除。 - 设置
l7-protocol-ports,可设置特定应用协议尝试解析的端口号列表。默认情况下 DNS 仅解析 53、5353 两个端口的流量,TLS 仅解析 443 端口的流量,其他所有应用协议解析 1-65535 全端口流量。这个配置项对特征不明显的协议非常有效,例如当你非常清楚环境中 Redis 协议的所有通信端口号时,设置该配置项能避免误解析,从而也就能避免存储由于误解析生成的脏数据。
对于指标数据 flow_metrics:
- 设置
l4_performance_enabled,可关闭对高级网络性能指标的计算和存储。高级网络性能指标包括network_*表中的时延、性能、异常指标(即吞吐类以外的所有指标),具体指标列表详见文档。 - 设置
l7_metrics_enabled,可关闭对应用性能指标的计算和存储。应用性能指标对应application_*表。
对于性能事件 event.perf_event:
- 设置
io-event-collect-mode,可调整采集的文件读写事件范围。设置为 0 完全关闭采集,设置为 1 仅采集在 Request 生命周期内发生的文件读写,设置为 2 采集所有文件读写。默认值为 1,聚焦于监控文件读写对 Request 性能的影响。 - 设置
io-event-minimal-duration,可通过设置耗时阈值,来调整记录的文件读写事件的多少。默认此值为 1ms,仅记录读写耗时大于等于 1ms 的事件。调高此值能降低事件的数量。
对于持续剖析 profile:
- 设置
on-cpu-profile.disabled,可彻底关闭持续剖析功能。
此外,我们还能通过一些配置项从源头处减少数据量:
- 设置
tap_interface_regex,控制采集流量的网卡列表。当我们不希望采集某些虚拟网卡或物理网卡的流量时,可调整此配置。 - 设置
dispatcher_bpf,可使用 BPF 表达式过滤采集的流量。例如当我们确认所有 9999 端口的流量都是监控数据传输的流量,如果我们对此不关心,可配置此项为not port 9999来屏蔽对这些流量的采集 - 设置
kprobe_blacklist,可设置一个端口号黑名单,使得 eBPF kprobe 能利用这个端口号列表过滤(丢弃)Socket 数据,减少调用日志的数据量。
# 6. 红色:设置过载保护阈值
最后我们来看看红色的配置项。我们不希望极端情况下 agent 输出过量的流日志和调用日志,避免导致占用过大的带宽;也不希望单个 server 的写入量过大,避免导致 ClickHouse 的过载。因此我们暴露了如下配置项:
l4_log_collect_nps_threshold,用于控制 agent 发送流日志的最大速率。当实际待发送的流日志超过此速率时,agent 会进行主动的丢弃,此时通过监控deepflow_system.deepflow_agent_flow_aggr中的drop-in-throttle指标可监控此丢弃行为。l7_log_collect_nps_threshold,用于控制 agent 发送调用日志的最大速率。当实际待发送的调用日志超过此速率时,agent 会进行主动的丢弃,此时通过监控deepflow_system.deepflow_agent_l7_session_aggr中的throttle-drop指标可监控此丢弃行为。l4-throttle,用于控制单个 server 副本写入流日志的最大速率,当设置为 0 时使用throttle配置项的值。当实际待写入的流日志超过此速率时,server 会进行主动的丢弃,此时通过监控deepflow_system.deepflow_server_ingester_decoder中的drop_count指标(使用msg_type: l4_log过滤)可监控此丢弃行为。l7-throttle,用于控制单个 server 副本写入调用日志的最大速率,当设置为 0 时使用throttle配置项的值。当实际待写入的调用日志超过此速率时,server 会进行主动的丢弃,此时通过监控deepflow_system.deepflow_server_ingester_decoder中的drop_count指标(使用msg_type: l7_log过滤)可监控此丢弃行为。